Visualisierung des Abstimmungsverhaltens
Aktualisiert mit den neuen Daten vom 22.03.2018
Kann man das Verhalten der Abgeordneten in den Abstimmungen des Bundestages visuell darstellen und denen anderer gegenüberstellen?
Eine derartige Visualisierung, wenn sie denn „vernünftig“ ist, erlaubt es zum Beispiel, dass man Gemeinsamkeiten zwischen Fraktionen, Parteien sowie zwischen Opposition und Regierungsfraktion finden könnte (oder eben Unterschiede).

Als Datenwissenschaftler frage ich mich dann sofort, ob man zwischen den Mitgliedern des Bundestages ein quantitatives Ähnlichkeitsmaß formulieren könnte. Hat man so ein Maß, dann könnte man sogar auf Abweichlersuche gehen, die wären dann nämlich besonders unähnlich zum Rest ihrer Fraktion.
Noch besser ist es, wenn man die Abgeordneten dar als Zahlenvektor darstellen könnten (man das dann Einbettung). Wenn wir Vektoren haben, also eine räumliche Darstellung der Abgeordneten, dann folgt sofort ein Ähnlichkeitsmaß: Je näher desto ähnlicher.
Das machen wir jetzt.
Abstimmungsverhalten als Einbettung
Auf der Seite des Bundestages werden regelmäßig das Abstimmungsverhalten der Mitglieder des Bundestags festgehalten (siehe hier). Damit ergibt sich automatisch eine numerische Darstellung. Und zwar stellt man jeden Abgeordneten als Sequenz seiner Abstimmungen dar. Wobei ein „Ja“ als $1$ kodiert wird, ein „nein“ als $-1$ und alles andere (ungültig, nicht abgegeben, unbekannt) als eine $0$.
Wenn wir also $5$ Abstimmungen hatten und der Abgeordnete M hat in der Reihenfolge mit Ja, Nein, Ja, Ja, „Merkel muss weg“ abgestimmt, dann wäre der dazugehörige Vektor $[1, -1, 1, 1, 0]$.
Es sind natürlich noch weitere Darstellungen möglich, am naheliegensten wären biographische Daten oder eine Auswertung des Verhaltens während der Sitzungen, etwa eine Sprachanalyse oder sogar die Interaktionen als Merkmalsvektor darzustellen.
Die Darstellungen anhand des Abstimmungsverhaltens lässt die $709$ Abgeordneten als Vektoren der Dimension $18$ erscheinen.
Den Bundestag visualisieren
Es ist nun für die meisten schwer sich Punktwolken in Dimensionen größer als drei vorzustellen. In der Regel schauen wir uns maximal eine dreidimensionale Visualisierung an, die auf einen zweidimensionalen Raum, nämlich dem Papier, eingebettet ist. Über Strategien wie Farbwahlen, Kontraste, Animationen oder auch interaktiven Elementen vermag man es auch darüberhinaus zu gehen.
Jedoch ist die Standardstrategie bei Datenwissenschaftler eine sogenannte Dimensionsreduktion durchzuführen. Hier führe ich zwei verschiedene durch:
- die den Naturwissenschaftlern bekannten Prinzipalkomponentenanalyse (PCA);
- das weniger bekannte t-SNE (en-wiki).
Die Algorithmen sind von ihrer Idee her komplett unterschiedlich und haben auch ganz verschiedene Charakteristika. Wichtig ist es zu wissen, dass t-SNE lokale Beziehungen besser darstellt. Die gehen bei der PCA nämlich verloren. Der Nachteil ist es jedoch, dass t-SNE teurer zu berechnen ist, also in der „Big Data“ Welt häufig fehlschlägt, und schwerer zu interpretieren sein könnte.
PCA + Auswertung
Benutzt man also die PCA um die Vektoren der jeweiligen Abgeordneten auf zwei Dimensionen zu bringen, dann ergibt eine Zeichnung eben dieser das folgende Bild:
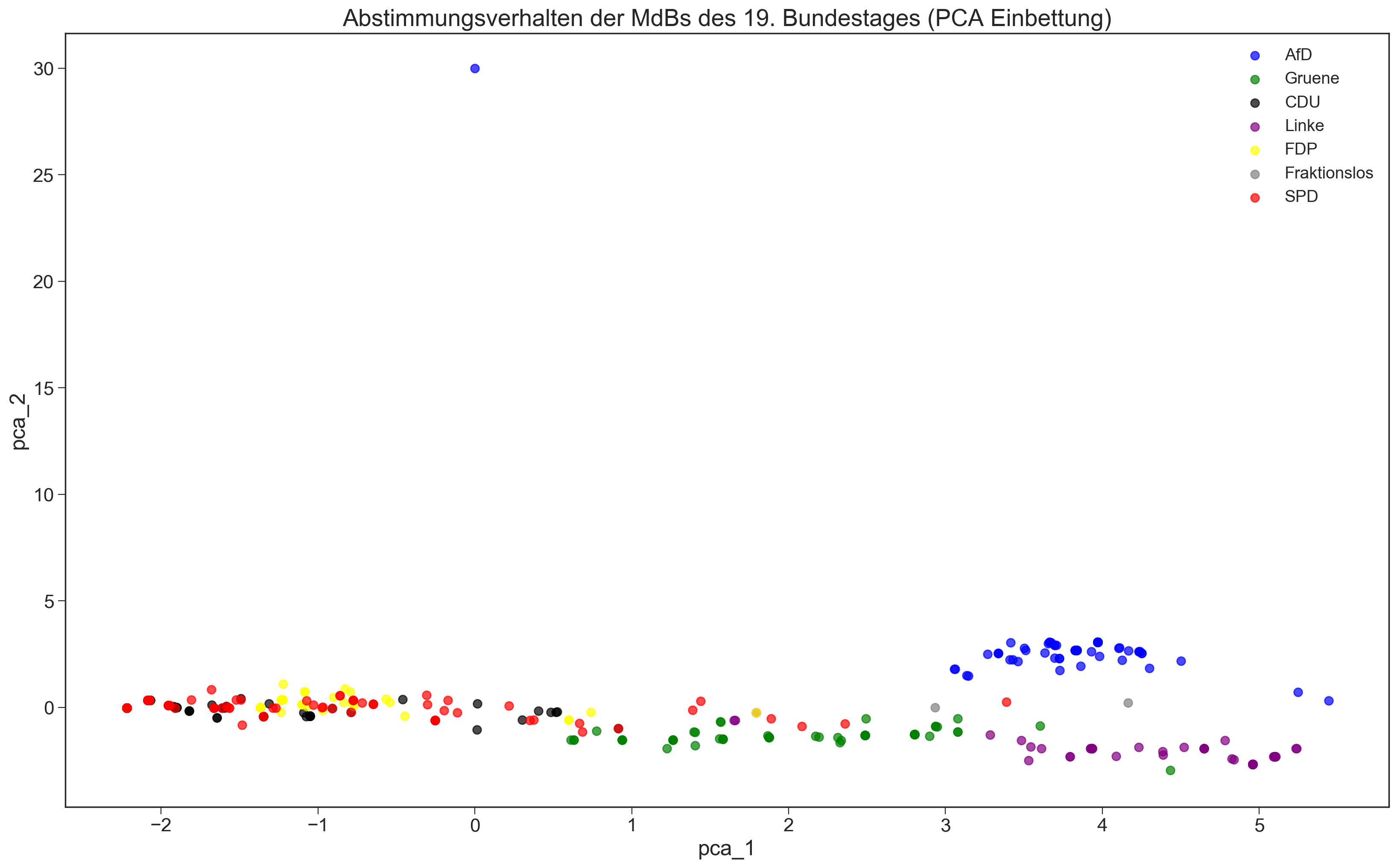
Dieses Bild ist nicht sonderlich interessant1. Die x-Achse ist die erste Hauptkomponente (= die wichtigste), die wohl eine Art „konform-opposition“ Achse angibt. Die andere Achse scheint wohl einen Abweichler darzustellen. Es handelt sich hier um Hr. Ulrich Oehme, MdB. Sein Abstimmungsmuster ist:
[0., -1., 1., 0., -1., 0., 0., 0., 0., -1., 0., 0., 1.,
-1., 0., -1., 0., 1.]
Wie man, in anderer Reihenfolge, hier findet. Er hat schlicht sehr häufig nicht abgestimmt.
t-SNE + Auswertung
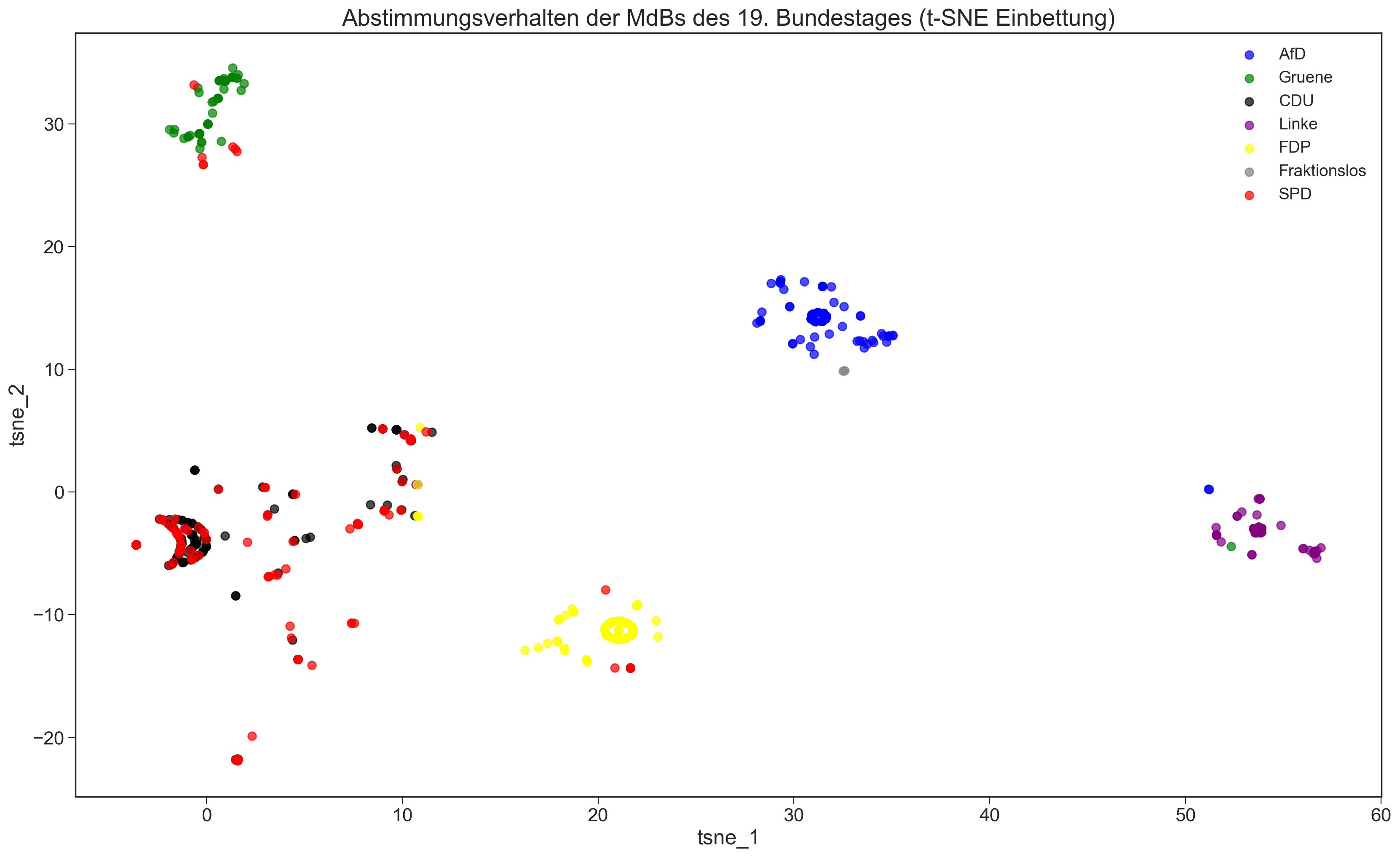
Dieses Bild ist nun deutlich interessanter, man sieht deutlich wie sich die Abgeordneten der Fraktion sowie der Regierung „zentrieren“. Man sieht eine Gruppe der SPDler bei den Grünen und bei der FDP (ob das die Hamburger sind?).
Interessant ist die Gruppe der Fraktionslosen, die sich wieder der AfD zugewandt haben. In einer früheren Visualisierung, mit weniger Daten, wichen diese auch klar ab.
Der Abweichler ist nun Hr. Frank Pasemann (Profil), MdB, mit der Sequenz:
[-1., -1., -1., -1., -1., -1., -1., -1., -1., -1., -1., -1., 1.,
-1., -1., -1., -1., 1.]
Neinsager sagen „Nein!“ und daher findet der sich bei den Linken, nicht weil er „links“ ist.
Ausblick
Die erste Frage, die mir einfiel, war: „Wie stark äußert sich der Fraktionszwang konkret?“, was ich auf den selben Daten mittels einer Entropieanalyse lösen konnte. Das werde ich zeitnah als einen seperaten Artikel auf diese Seite stellen.
Es interessiert mich desweiteren, v.a. eine Sprach- und Verhaltensanalyse der Abgeordneten aus den Protokollen. Um diese strukturiert auseinander zu nehmen, brauche ich aber ein ganzes Wochenende (… oder mehr). Und das konkurriert derzeit mit der Lektüre von Texten der Ethik und politischen Philosophie.2
Übrigens kann man mehrere „Einbettung“ bzw. Merkmalsextraktionen miteinander mischen, indem man die entstehenden Vektoren aneinander kettet. Anfängern sei aber gesagt, dass man dann auch gewichten sollte (viele Algorithmen bieten dies an).
Anhang
Der Code findet sich hier, die Analyse findet sich in einen Jupyter Notebook.
Auszug t-SNE Visualisierung
from sklearn.manifold import TSNE
tsne = TSNE(2, n_iter=3000, random_state=1)
X_2d = tsne.fit_transform(X)
# 0 == AfD
# 1 == Grüne
# 2 == CDU
# 3 == Linke
# 4 == FDP
# 5 == Fraktionslos
# 6 == SPD
legends = ["AfD", "Gruene", "CDU", "Linke", "FDP", "Fraktionslos", "SPD"]
colors = ["blue", "green", "black", "purple", "yellow", "grey", "red"]
fig, ax = plt.subplots()
for i, (label, color) in enumerate(zip(legends, colors)):
X_class = X_2d[y == i]
ax.scatter(x=X_class[:, 0], y=X_class[:, 1], s=50, alpha=0.7, c=color, label=label)
plt.title("Abstimmungsverhalten der MdBs des 19. Bundestages (t-SNE Einbettung)")
plt.xlabel("tsne_1")
plt.ylabel("tsne_2")
plt.legend()
Abweichlersuche AfD
X_afd = X_2d[y == 0]
mu_afd = X_afd.mean(axis=0)
outlier = max(X_afd, key=lambda v: np.linalg.norm(v - mu_afd))
np.where(X_2d == outlier) # Gibt die Indexe der/des Abweichler an.
-
Übrigens erklärt die erste Achse ca. $63,22$% der Varianz und die zweite ca. $15,39$%. ↩
-
Man benötigt auch schlicht Muße. Das sture Lesen bringt bei derartigen Texten nicht viel. Ich meine hier auch speziell die Ethik von Kant für die man auch seine Epistemologie verstehen muss. Meine Haltung dazu ist „festina lente“ + „Kathedralen bauen sich nicht in kurzer Zeit”. :-) ↩